
Viver e trabalhar na Big Apple (apelido para Manhattan) vem com um aluguel alto.
Eu, assim como muitos dos cidadãos da cidade que vivem dentro de um armário abarrotado que chamamos de apartamento, procuro cortar gastos onde quer que eu possa. Não é segredo que um jeito de cortar despesas, pelo menos nos disseram, é cozinhar em casa em vez de comer fora o tempo todo. Como residente da cozinha do inferno (Hell's Kitchen - jogo de palavras com o nome do bairro no distrito de Manhattan), isso é quase impossível. Em todo lugar que eu olho tem um sushi bar, restaurante mexicano ou alguma pizzaria aparentemente deliciosa ao alcance de um braço e que pode quebrar minha força de vontade num piscar de olhos. Eu sou uma vítima disso mais do que gostaria de admitir. Bem, eu costumava ser vítima disso — até recentemente. Não querendo abrir mão das experiências gastronômicas que eu gostava tanto, eu decidi que iria fazer meu próprio dinheiro para financiar essas transações. Eu tenho comido em restaurantes, lanchonetes e outros de graça desde então.
Eu vou explicar a você como eu estou recebendo essas comidas grátis de alguns dos melhores restaurantes em Nova York. Eu vou admitir, é bastante técnico e nem todo mundo pode reproduzir minha metodologia. Você também vai precisar de um conhecimento básico em Ciência de Dados/Desenvolvimento de software ou muito tempo livre em mãos. Já que eu tenho o citado anteriormente, eu relaxo e deixo meu código fazer o trabalho por mim. Oh, e você adivinhou, também precisará saber como usar o Instagram.
Se você é parte do público técnico, eu vou abordar brevemente algumas das tecnologias e linguagens de programação que uso mas eu não vou fornecer nenhum código ou qualquer coisa assim. Eu vou explicar meu uso da regressão logística, florestas aleatórias (random forests), AWS e automação — mas não a fundo. Esse artigo será mais focado em teoria. Se você é um leitor leigo em programação, tudo aqui ainda pode ser feito, só vai levar um certo tempo e esforço. Esses métodos são tediosos e é por isso que decidi automatizar a maior parte deles.
Agora para entrarmos no assunto, eu vou começar com a resposta e depois vou para como eu cheguei lá.
O que eu fiz
Na era digital atual, um grande público no Instagram é considerado uma moeda valiosa. Eu também tinha escutado boatos de que poderia monetizar um grande número de seguidores — ou no meu caso — usá-los para pagar minhas refeições. Então fiz exatamente isso.
Eu criei uma página no instagram que exibia fotos de Nova York como skylines (panoramas), lugares icônicos, arranha-céus elegantes — o que quer que você diga. A página acumulou mais de 25 mil seguidores na região de Nova York e continua crescendo rapidamente.
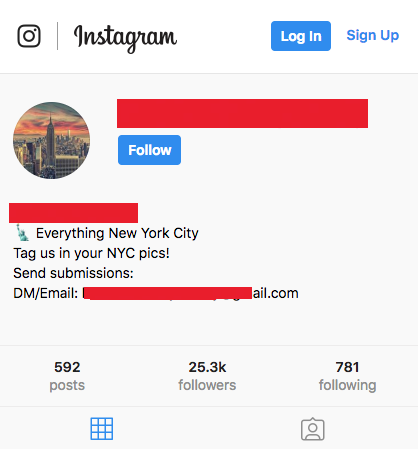
Eu entro em contato com restaurantes na região por meio da DM do Instagram e ofereço de um post a um review para meus seguidores em troca de uma consumação gratuita ou pelo menos um desconto. Quase todo restaurante que eu mandei mensagem veio até mim com um desconto ou um gift card. Muitos dos lugares tem um orçamento de marketing alocado pra esse tipo de coisa, então eles estavam felizes por me oferecer uma experiência gastronômica gratuita em troca de uma potencial promoção do negócio. Eu acabei dando algumas dessas refeições para meus amigos e familiares porque às vezes eu tinha muitas acumuladas na fila para conseguir usar comigo mesmo.
A beleza nisso é que eu automatizei a coisa toda. E eu quero dizer 100%. Eu escrevi um código que encontra essas fotos ou vídeos, faz uma legenda, adiciona hashtags, os créditos de onde a foto ou vídeo veio, elimina postagens ruins ou spam, posta o conteúdo, segue (follow) e deixar de seguir (unfollow) usuários, curte fotos, monitora minha caixa de email e o mais importante — as mensagens diretas e emails de restaurantes sobre uma potencial promoção. Desde a sua concepção, eu nem mesmo loguei na conta. Eu gasto zero segundos com isso. É essencialmente um robô que opera como um humano, mas o usuário comum não pode dizer a diferença. E como programador, eu posso sentar e adimirar o seu (e o meu) trabalho.
Como eu fiz
Eu vou mostrar a você como eu fiz o que eu fiz, de A à Z. Alguma coisa disso pode parecer senso comum, mas quando você está automatizando um sistema para agir como um humano, detalhes são importantes. O processo pode ser dividido em três fases: compartilhamento de conteúdo, growth hacking (marketing) e promoção de vendas.
O conteúdo
Agora, nenhum dos conteúdos dos meus posts são realmente meus. Eu re-compartilho o conteúdo de outras pessoas na minha página, com créditos para elas. Se alguém me pede para tirar sua foto, eu o faço na hora. Mas como estou buscando na página deles, eu só tenho recebido agradecimento — nunca o contrário.
Postar todo dia — várias vezes no dia — é indispensável. Esse é um dos principais fatores que o Instagram usa para determinar o quanto vão expor você para o público via Instagram Explore (a página da lupa). Postar todo dia, especialmente nos horários "de pico", é muito mais difícil e mais monótono do que você pode pensar. A maioria das pessoas desiste dessa tarefa depois de algumas semanas e perder mesmo que um dia ou dois pode ser determinante. Então, eu automatizei a coleta de conteúdo e o processo de compartilhamento.
- Obtendo fotos e vídeos no inventário
Eu primeiro pensei em configurar um extrator de imagens do Google Images ou Reddit para obter meu conteúdo. Um das grandes lutas que eu tive foi como particularmente o Instagram funciona com relação às dimensões das imagens que são postadas. Idealmente, é uma foto "quadrada", o que quer dizer que a largura é igual a altura, então ele vai rejeitar um post com algo fora de proporção. Isso tornou a recuperação de conteúdo bem desafiadora.
Por fim, eu decidi extrair diretamente de outros feeds no Instagram porque a foto viria precisamente na proporção exigida. Isso também me permitiu conhecer exatamente de onde a foto veio, o que será útil no processo de auto-creditação.
Eu coletei uma lista de cinquenta outras contas de Instagram que postavam fotos (com qualidade) de Nova York. Então eu configurei o extrator para ir até as contas e baixar o conteúdo delas. Junto com o atual conteúdo, eu extrai um monte de metadados que vieram com a foto como legenda, número de curtidas e localização. Eu configurei o extrator para rodar todo dia as 03:00 horas ou quando meu inventário estivesse vazio.
Com isso, eu agora tenho um local central com conteúdo relacionado no formato correto.
- Decidindo automaticamente qual conteúdo é "bom" ou "ruim"
Nem todos os posts de todo mundo são "re-compartilháveis". A todo o tempo, pessoas estão tentando vender alguma coisa, atingir outra página ou pode ser apenas um conteúdo ruim ou não relacionado. Pegue esse dois posts como exempo:
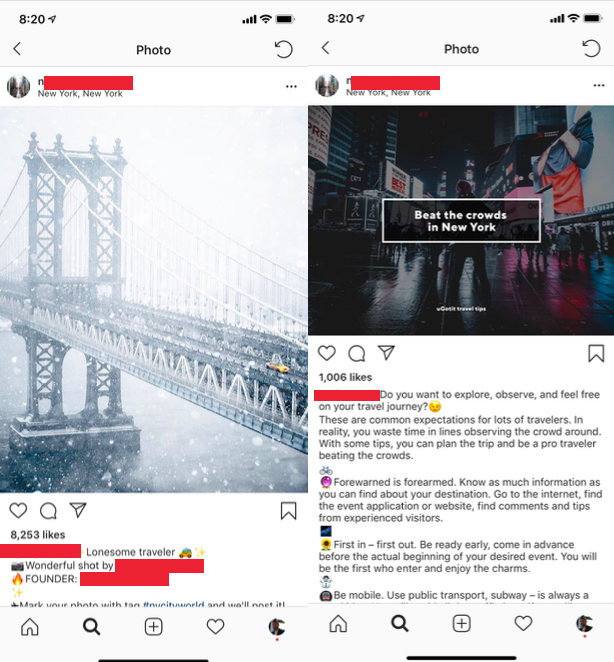
Os dois são da mesma conta sobre Nova York no Instagram. O da esquerda é um post normal no seu nicho — um que eu ficaria feliz em re-compartilhar na minha página. O da direita, contudo, é um anúncio. Sem nenhum contexto, se eu colocar isso na minha página vai ser bem confuso ou fora de lugar. A legenda foi cortada mas na verdade o post está promovendo um aplicativo baseado em Nova York. Você pode ver a diferença no número de curtidas — 8200 vs 1000. Eu preciso ser capaz de eliminar postagens como a da direita e re-compartilhar postagens como a da esquerda de forma automática.
Portanto, eu não posso re-compartilhar cegamente todo o conteúdo que eu extraio. E já que isso vai ser um processo automático, eu preciso criar um algoritmo que vai eliminar o ruim do bom. A primeira parte do meu "limpador" tem algumas regras embutidas no código e a segunda é um modelo de machine learning (aprendizado de máquina) que refina o conteúdo ainda mais.
Limpador Parte 1 — Regras no código
A primeira coisa que eu fiz foi refinar meu inventário em algumas diretrizes específicas dos metadados. Fui bastante rigoroso porque não há falta de conteúdo para compartilhar. Se houvesse mesmo uma pequena bandeira vermelha, eu descartava a foto. Eu sempre posso extrair mais conteúdo, mas se meu algoritmo postar algo com spam ou conteúdo impróprio, talvez milhares de pessoas vejam antes que eu reconheça o problema e remova o conteúdo.
O passo preliminar foi fazer meu algoritmo olhar para a legenda. Se o texto incluísse algo relacionado a "link na bio" ou "compre agora", "por tempo limitado" ou algo assim, eu imediatamente descartava o conteúdo. Esses são os típicos posts para vender alguma coisa mais do que conteúdo de qualidade para entretenimento.
A próxima coisa que eu olhei foi se os comentários estavam desativados. Se estivessem, eu descartava a foto. Comentários desativados pela minha experiência estão relacionados com posts controversos e não valia o risco.
A última coisa que eu vi foi se havia mais de uma pessoa marcada na foto. Muitas vezes, uma marcação na imagem é um crédito para de onde veio a foto então, eu na verdade achava isso benéfico. Mas se a foto tinha múltiplas marcações, poderia levar a uma confusão quando chegasse a hora de creditar ou saber qual o propósito do post.
Com essas regras, eu fuiz capaz de pegar muito dos posts com spam e conteúdo indesejável e descartar da minha pasta. No entanto, só porque um post não está vendendo algo, não quer dizer que seja um bom post, em termos de qualidade. Também, minhas regras de código talvez deixassem passar algum "salesy content" (vendas escondidas no texto) , então eu queria passar o conteúdo por um modelo secundário assim que acabasse a parte um.
Limpador Parte 2 — Modelo de Machine Learning
Enquanto examinava meu repositório de fotos agora mais limpo, percebi que ainda havia alguns itens remanescentes que não eram particularmente desejáveis para postar. Eu não seria capaz de sentar aqui e manualmente remover os conteúdos ruins, afinal, eu planejei que isso seria completamente automatizado. Eu queria rodar outro teste em cada um dos conteúdos.
Eu tinha uma tonelada de informações em cada um dos posts, incluindo número de curtidas, legendas, data do post e muito mais. Minha intenção original era tentar prever quais fotos ganhariam mais curtidas. No entanto, a questão era que grandes contas tinham naturalmente mais curtidas, então isso não era um bom termômetro. Minha próxima ideia era fazer com que a variável de resposta fosse igual a razão de curtidas (número de curtidas/número de seguidores) e tentar prever isso. Depois de olhar cada foto e sua respectiva razão, eu ainda não confiava na correlação. Eu ainda não sentia que altas razões significavam necessariamente melhores fotos. Só porque uma conta era "popular" não significava que tinha conteúdo melhor do que um relativamente desconhecido fotógrafo com poucas curtidas. Eu decidi mudar minha perspectiva de um modelo de regressão para um modelo de classificação e simplesmente decidir se uma foto é boa o bastante para ser um post ou não — simples sim ou não.
Antes de olhar até qualquer outro metadado, eu extrai uma grande quantidade de fotos e manualmente passei por cada uma, marcando-as com 0 (ruim) ou 1 (boa). Isso é extremamente subjetivo, então eu estou teoricamente criando um modelo da minha própria consciência. Entretanto, parece haver um concenso universal sobre o que é considerado um conteúdo favorável e o que não é.
Eu gerei meu próprio conjunto de dados. A variável de resposta era 0/1 (ruim/bom) com um grande número de recursos. Os metadados de cada post me deram as seguintes informações:
Legenda
Número de curtidas
Número de comentários
Foto ou vídeo
Número de visualizações (para vídeos)
Data de publicação
Número de seguidores da conta dona do post
Dessas sete variáveis explanatórias, eu desenvolvi mais alguns recursos que eu pensei serem úteis. Por exemplo, eu mudei o número de comentários e curtidas para razões contra os seguidores. Eu extrai o número de hashtags da legenda e transformei em sua própria coluna, e fiz a mesma coisa com o número de contas marcadas na legenda. Eu limpei e vetorizei o resto da legenda para ser usada em processamento de linguagem natural (NLP em inglês). Vetorizar é o processo de remover palavras periféricas (como artigos e conjunções) e converter o restante em campos numéricos que podem ser analizados matematicamente. Depois de tudo dito e feito, eu tinha os seguintes dados resultantes:
Variável de resposta:
Razão do Post (0/1)
Variáveis explanatórias:
Legenda vetorizada
Número de marcações
Número de hashtags
tamanho da legenda
Se a legenda foi editada
Tipo de mídia
Razão de visualizações de vídeo/número de dias desde a postagem
Razão de comentários/número de dias desde a postagem
Eu brinquei com uma série de algoritmos de classificação, como Máquinas de Vetores de Suporte (support vector machines) e Florestas Aleatórias (random forests), mas cheguei a uma regressão logística básica. Eu fiz isso por algumas razões, a primeira sendo a Navalha de Ockham — às vezes a resposta mais simples é a correta. Não importa como eu rodei e re-projetei os dados, a regressão logística teve um desempenho melhor em meu conjunto de testes. A segunda e mais importante razão foi que, diferente de alguns outros algoritmos de classificação, eu posso configurar uma pontuação limite enquanto faço predições. É comum para algoritmos de classificação produzir uma classe binária (no meu caso 0 ou 1) mas a regressão logística na verdade produz um decimal entre 0 e 1. Por exemplo, a razão de um post pode ser 0.83 ou 0.12. É comum configurar o limite em 0.5 e classificar tudo maior que isso como 1 e tudo abaixo como 0, mas como eu tinha uma abundância de mídia disponível, eu fui extremamente rígido no meu limite e configurei para 0.9 e rejeitei tudo que ficou abaixo dessa referência.
Depois de implementar meu modelo, o inventário de fotos e vídeos estava A) limpo por uma série de regras rígidas e depois B) somente o melhor dos melhores foi escolhido pelo meu algoritmo de regressão logística. Eu agora posso passar para a etapa de legendar e creditar cada post.
Auto-legenda e auto-creditação
Eu agora tinha um sistema que recolhia automaticamente conteúdo relevante e removia fotos destoantes ou de spam — mas eu não estava pronto ainda.
Se você já usou o instagram antes, você sabe que cada post possui uma legenda que existe abaixo da foto ou vídeo. Sendo que não posso na verdade ver essas fotos, nem tenho tempo para sentar e legendar cada uma, eu precisava criar uma legenda genérica que pudesse ser usada por qualquer foto.
A primeira coisa que eu fiz foi criar um template final. Se parece mais ou menos com isso:
{LEGENDA}
.
.
.
Credito: {CREDITO}
.
.
.
{HASHTAG1 HASHTAG2 ... HASHTAG30}
Onde os três conjunto de {} precisavam ser preenchidos pelo meu script. Vamos examinar os três, um por um.
1 - Legenda
Eu criei um arquivo de texto com um número pré-definido de legendas genéricas que poderiam ser usadas com qualquer imagem. Eram citações sobre Nova York, questões gerais ou elogios básicos. Algumas delas incluiam:
Quem pode dizer o nome desse lugar?
Nos conte qual o seu bar favorito em Nova York nos comentários!
"Você não viveu até morrer em Nova York" - Alexander Woollcott
Para cada post, uma das minhas legendas era aleatoriamente escolhida. Eu tenho uma lista grande então não me preocupei em alguma delas ser usada demais ou ser sobreposta. Então, para nosso exemplo, vamos pegar a primeira — "Quem pode dizer o nome desse lugar?".
2 - Crédito
Essa foi uma das tarefas mais difíceis — creditar automaticamente a fonte. O que foi particularmente complicado foi que a página do Instagram de onde a mídia veio não era necessariamente a pessoa certa a se creditar. Frequentemente, aquelas contas também estavam re-compartilhando o conteúdo e creditando os donos em sua legendas ou marcando-os nas fotos.
Eu decidi que eu ia creditar a conta que gerou a foto não importasse como. Eu adicionaria então mais créditos se eu pudesse decifrar o dono original também. Senti que eu cobriria todas as minhas opções desse modo.
Dê uma olhada neste post de @likenewyorkcity no Instagram. Podemos ver que mesmo que ele/ela tenha compartilhado, o real dono é @geoffrey.parry que está marcado na foto e mencionado na legenda.

Idealmente, eu gostaria que meu código fosse capaz de olhar essa foto e retornar:
Credito: @likenewyorkcity/@geoffrey.pattyA primeira parte disso é fácil; apenas inserindo cada conta de onde veio. A segunda parte era um pouco mais desafiadora.
Eu usei REGEX (expressões regulares) para olhar para palavras-chave como "por" ou "foto:" e depois procurei pelo símbolo "@" que seguia logo depois. Daqui, Eu peguei o username (nome da conta) e acreditei que essa era a segunda parte do meu crédito.
Se nenhuma dessas palavras-chave existiam na legenda, eu checava se tinha alguém marcado na foto. Se tivesse, eu imaginava que mereciam o crédito. Eu entendo que esse é um método imperfeito, mas na maioria das vezes é por isso que alguém foi marcado e foi um risco que valia a pena.
Eu frequentemente capturo exatamente o crédito certo. Na verdade, muitas vezes as pessoas comentaram nas minhas fotos dizendo "obrigado por compartilhar!"(Eu adicionei um exemplo disso mais abaixo).
3 - hashtags
O Instagram permite que você adicione 30 hashtags em sua foto que serão apresentadas no feed de hashtags. Eu criei um arquivo com mais de 100 hashtags relacionadas:
#NYC #NY #NewYorkCity ... #ThePlaza #NYCInstagram #NYYankeese aleatoriamente escolho 30 para adicionar cada vez. Eu fiz isso para que depois de um tempo, eu possa comparar quais hashtags me levam a um maior número de curtidas.
4 - Template final
Depois de finalizar os três passos que eu citei anteriormente, eu fui capaz de preencher meu template e ter uma legenda que pode ser usada em qualquer post.
Quem pode dizer o nome desse lugar?
.
.
.
Credito: @likenewyorkcity/@geoffrey.parry
.
.
.
#newyorkig #city_of_newyork #ig_newyork#newyorkgram #nycgo #nybucketlist#nyclives
#nypostnyc #streetsofnyc#winterinnewyork #downtownnyc#brooklynheights #newyork_photoshoots
#newyork_originals #nyloveyou#nycityworld #newyorkbound#newyorkminute #imagesofnyc
#travelnyc #nyc_exporers #nycbuildings#oneworldtradecenter #flatironbuilding
#grandcentralterminal #newyorkknights #bigapplenyc #newyorknewyork#manhattanbridge
#brooklynbridge
Aqui um exemplo de um dos meus produtos finais:
Eu usei uma legenda genérica que pode acompanhar qualquer foto de Nova York. Eu creditei tanto a conta da onde veio a foto quanto a fonte original. Se você olhar nos comentários, verá que o dono original me agradeceu por compartilhar. E eu adicionei 30 hashtags para dar um impulso no meu post também.
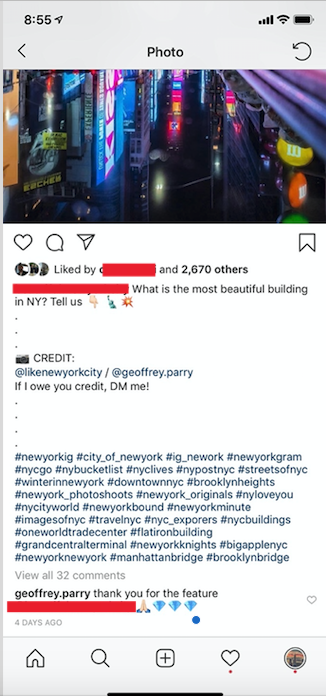
Postagem
Eu agora tinha um repositório central de mídia relevante e um processo de geração de legenda para cada um desses posts. Agora, é hora de fazer apenas isso — postar.
Eu rodei uma instância EC2 na AWS para hospedar meu código. Eu fiz essa escolha porque é mais confiável que uma máquina pessoal — está sempre ligada e conectada à internet e eu sabia que tudo ia caber dentro dos limites da conta gratuita.
Eu escrevi um script Python que pega aleatoriamente uma dessas fotos e gera uma legenda depois dos processos de extração e limpeza estarem completos. Usando minha API, fui capaz de escrever o código que faz o post pra mim. Eu agendei tarefas no cron para executar por voltas 8:00 horas, 14:00 horas e 19:30 horas todo dia.
Nesse ponto, eu havia concluído a automação do processo de busca e postagem de conteúdo. Eu não tenho mais que me preocupar com buscar mídia e postar todo dia, está sendo feito para mim.
Crescendo meus seguidores
Não é suficiente apenas postar — eu preciso implementar algumas técnicas para aumentar os meus seguidores também. E já que eu nunca estaria na conta fazendo qualquer coisa manualmente, eu teria que automatizar isso também. A idéia era fazer com que minha conta fosse exposta a um público interessado através de interação direta com esse público.
O script de interação que eu escrevi roda de 10:00 horas à 19:00 horas (horário do leste), o intervalo de tempo que eu acreditava ser o mais ativo no Instagram. Ao longo do dia, minha conta metodicamente segue, deixa de seguir e curte posts de usuários relevantes para que o mesmo seja feito de volta.
Seguindo (Mais Ciência de Dados)
Se você usa Instagram, eu tenho certeza que você já fez parte disso antes, percebendo isso ou não. Esse método é muito conhecido por contas que estão tentando aumentar seus seguidores. Um dia você segue uma página de Instagram interessante sobre fitness e no dia seguinte, você está sendo seguido por um monte de bodybuilders e modelos fitness. Isso parece extremamente trivial, e é, mas é muito efetivo.
A questão aqui é que você não pode simplesmente seguir quantos quiser no Instagram. O algoritmo deles é bem rígido, então eles te cortam ou mesmo banem sua conta se você passar dos limites e seguir muitas contas num único dia. Adicionalmente, você pode seguir no máximo 7500 usuários de uma vez no Instagram. Depois de muito teste, eu descobri que você pode seguir 400 pessoas e deixar de seguir 400 em um único dia. Além do mais, cada follow é extremamente precioso. Você não quer gastar um follow com alguém improvável de te seguir de volta porque você tem um número X de pessoas que você pode seguir em um dia. Eu decidi capturar os metadados da minha atividade e criar um modelo para prever a probabilidade de alguém de seguir de volta, então eu não desperdiçaria um precioso follow em alguém que provavelmente não retornaria o favor.
Eu gastei alguns minutos manualmente recolhendo as 20 maiores contas no mesmo nicho que eu. Eu não tinha nenhum dado inicial, então nas primeiras semanas eu faria essas ações manualmente para aumentar meus seguidores, mas o mais importante, eu precisava capturar tantos metadados quanto possível para então poder fazer meu modelo.
Eu percorri mais de 20 contas relacionadas e segui os usuários que seguiam essas contas, curtiam suas fotos ou comentavam em seus posts. Com cada follow, eu capturava o máximo de metadados que podia sobre o usuário em um arquivo CSV. Alguns desses metadados incluíam a razão do número de pessoas que a conta seguia/seguidores, se era uma conta pública ou privada ou se tinha foto de perfil ou não. Todo dia, meu script percorria esse CSV e rotulava a variável de resposta, que era se os usuários seguiram de volta ou não. Eu dei a cada usuário dois dias inteiros antes de rotulá-lo(a) com 0, 1 ou 2 — 2 sendo o resultado mais desejado. 0 indicava que o usuário não seguiu de volta, 1 indicava que fui seguido de volta mas o usuário não interagiu nos meus 10 últimos posts (curtir ou comentar) e 2 indicava que fui seguido de volta e o usuário interagiu nos meus últimos posts. Meu conjunto de dados parecia algo assim:
Variável de resposta:
Seguir de volta (0,1,2)
Variáveis explanatórias:
Veio de (a conta da qual o usuário foi extraido)
Método (se eles curtiram/comentaram/seguiram o usuário da variável de cima)
Timestamp (data e hora)
Privado vs Público
Faltando foto de perfil
É um perfil de negócios
razão Seguindo/Seguidores
biografia do perfil
contagem de mídia
Gênero (predito através do nome usando um pacote de terceiros)
Antes de rodar esses dados no meu modelo de Machine Learning, eu fiz algumas análises nos dados exploratórios e descobri que:
Pessoas que curtem e comentam são menos propensas a me seguir do que as pessoas que seguem as contas, mas são mais engajadas comigo. Isso me diz que embora elas sejam menos abundantes em quantidade, mas bem maiores em qualidade.
Seguir pessoas pela manhã resultava em uma maior taxa de "seguidas de volta" do que durante a noite.
Contas públicas são mais propensas a me seguir de volta que contas privadas.
Mulheres são mais propensas a seguir de volta uma conta sobre Nova York do que homens.
Aqueles que seguem mais pessoas do que tem de seguidores (razão Seguindo/Seguidores > 1.0) tem uma propensão maior a me seguir de volta.
A partir desses insights eu fui capaz de refinar minha busca inicial por usuários. Eu ajustei minhas configurações para seguir apenas pela manhã e procurar primariamente por mulheres. Agora eu estava finalmente pronto para fazer meu modelo de Machine Learning prever a probabilidade de eu ser seguido de volta baseada nos dados do usuário antes mesmo de interagir com ele. Isso me permite não gastar um dos meus já limitados follows diários em alguém que tem uma chance muito pequena de me seguir de volta.
Eu escolhi usar um algoritmo de floresta aleatória para classificar o resultado das "seguidas de volta". Eu originalmente estava usando várias árvores de decisão diferentes antes de ter uma estrutura definida ou variável de resultado, porque queria ver os fluxogramas visuais que vêm junto com eles. A Floresta Aleatória é um aprimoramento da árvore de decisão que fornece vários ajustes para corrigir muitas das inconsistências nas árvores individuais. Eu estava vendo consistentemente uma precisão de mais de 80% em meus dados de teste após modelar meus dados de treinamento, então foi um modelo eficaz para mim. Eu implementei isso no meu código do extrator de usuário para otimizar o uso de follows e vi um crescimento tremendo no meu número de seguidores.
Deixando de seguir
Depois de dois dias, eu deixaria de seguir quem eu havia seguido. Isso me dava tempo suficiente para saber se iam me seguir de volta ou não e também me permitiu coletar dados para continuar crescendo.
Você tem que deixar de seguir as pessoas que você seguiu por dois motivos. O primeiro é que você não pode seguir mais de 7500 contas de uma vez. O segundo é porque — embora artificial — você quer manter o valor da sua razão Seguidores/Seguindo o mais alto possível pois isso é um sinal de uma conta mais desejável.
Essa é uma tarefa fácil porque não há decisões a serem tomadas.Você segue 400 pessoas num dia e dois dias depois, deixa de seguir essas mesmas pessoas.
Curtindo
Curtir também pode ajudar sua conta. Eu não coloquei muito esforço em escolher as fotos para curtir porque não contribui tanto para o aumento de seguidores quanto o método de seguir descrito acima.Eu simplesmente dei um conjunto pré-definido de hashtags, para que os feeds fossem percorridos e fotos curtidas na esperança dos usuários retribuírem o favor.
Auto-vendas
Nesse estágio, eu tenho um Instagram robótico auto-sustentável. minha página de Nova York, por si só, busca conteúdo relevante, excluindo potenciais posts ruins, gera créditos e legendas e posta durante o dia. Além disso, de 10:00 horas às 19:00 horas, cresce sua presença online quando automaticamente, curte, segue e deixa de seguir um público interessado que foi posteriormente redefinido por alguns algoritmos de ciência de dados. A melhor parte é que parece mais humano que a maioria das contas nesse nicho.
Por um mês ou dois, eu relaxei e assisti meu produto crescer. Eu veria um aumento de algo entre 100 e 500 seguidores por dia, o tempo todo, enquanto desfrutava de algumas belas fotos da cidade que eu amo.
Eu podia ir cuidar da minha vida, trabalhar, sair com os amigos, ver um filme — nunca tendo que me preocupar com gastar qualquer segundo que seja em crescer minha página manualmente. Ela tinha a fórmula para fazer seu trabalho enquanto eu fazia o meu.
Uma vez que eu tinha 20 mil seguidores, eu decidi que era hora de usar a página pra conseguir algumas refeições grátis. De novo, eu automatizei o discurso de vendas também.
Eu fiz um template de uma DM para o Instagram onde eu tentei ser o mais genérico possível. Eu queria ser capaz de usar a mesma mensagem caso fosse um restaurante, um teatro, um museu ou uma loja. Isso foi o que eu fiz:
Olá {NOME DA CONTA}
Meu nome é Chris e eu administro esta conta do Instagram! Nós temos mais de {NUMERO DE SEGUIDORES}
seguidores na região de Nova York e muitos deles comentam nos meus posts ou me mandam mensagens
perguntando sobre o melhor restaurante para jantar, melhores bares para ir ou atrações para visitar.
Nós adoraríamos fazer algum tipo de acordo com você para promover seu estabelecimento. Nós postaríamos
o seu estabelecimento, endereço, marcaríamos sua página e recomendaríamos a todos para conferir.
O post ficará na página para sempre e você pode até escrever uma legenda e fazer o post e me enviar
se quiser. Nós também postaríamos vocês em nossos stories do Instagram com um link swipe-up
("arrasta pra cima") direcionando para o seu site. Em troca, eu gostaria de pedir uma experiência
gratuita, um pequeno gift card, desconto ou cupom para o seu estabelecimento.
Se você tiver interesse, por favor, me responda aqui ou me mande um email em
{EMAIL}
Obrigado!
Chris
Aqui, eu só precisava inserir o nome da conta, email e o número de seguidores que eu possuía no momento da construção da mensagem.
Meu objetivo era encontrar instagrams de negócio e mandar pra eles meu discurso. Um perfil de negócio é um pouco diferente de um normal — permite ao usuário adicionar email, número de telefone, localização e outros botões na página. Mas, o mais importante, ele tem uma categoria bem no perfil.
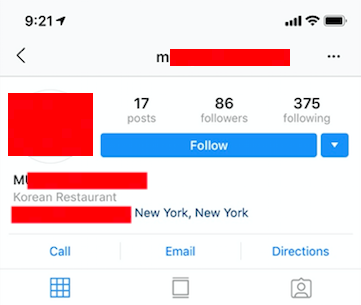
O exemplo acima é de um perfil de negócio. Logo abaixo do nome no canto superior esquerdo, diz "Restaurante Coreano" e tem botões de ação como ligar, email e localização.
Eu escrevi um script em Python que procura por essas páginas e automaticamente envia a elas a mensagem da minha conta. O script recebe dois parâmetros, uma hashtag inicial e um texto para procurar por categorias. No meu caso, eu usei a hashtag "Manhattan" e o texto "restaurante".
O que esse script faz é ir até o feed da hashtag e carregar um monte de fotos. Em seguida, percorre os posts até encontrar um que possui usuários marcados na foto. Se encontrar, ele checa se as contas marcadas são de perfis de negócio, caso sejam, confere a categoria. Se a categoria incluir a palavra "restaurante", ele manda a minha mensagem. A parte legal sobre perfis de negócio é que eles frequentemente tem emails em suas páginas. Se eles possuem, eu automaticamente mando um email logo depois da mensagem na DM do Instagram. Eu posso mudar a hashtag para algo como #TimesSquare e o texto para, digamos, "museu" se meus objetivos mudarem com o tempo.

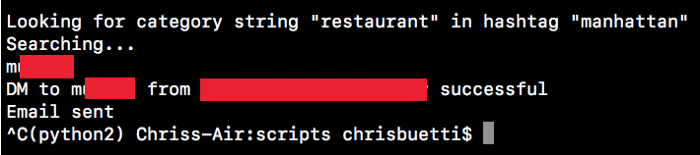
Se eu for na minha conta, verei a mensagem que o script gerou e enviou.
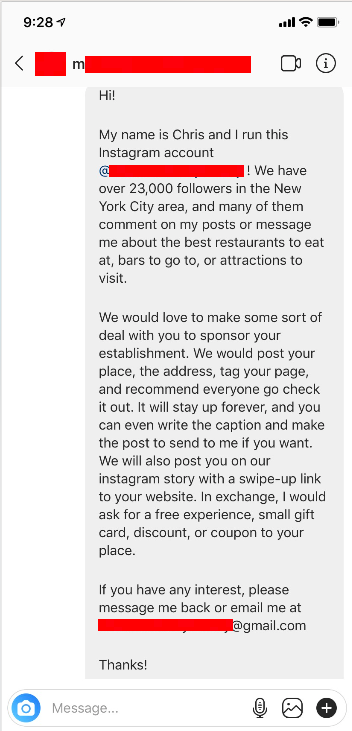
E seu for na minha caixa de saída do Gmail, eu verei:
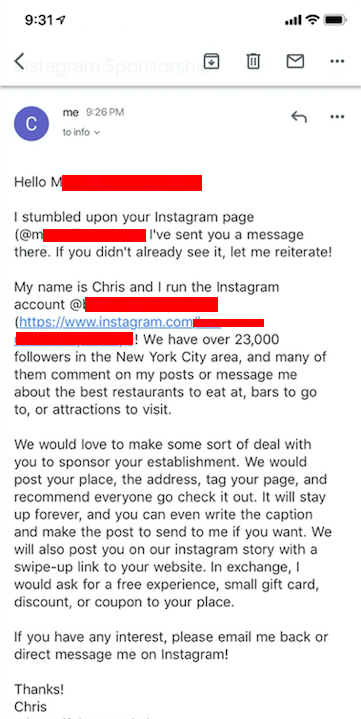
Por fim, eu tenho um script que monitora minha caixa de entrada por respostas e me alerta quando acontece. Se há uma resposta, eu finalmente faço algum trabalho manual e negocio com meu potencial cliente.
Enquanto isso, o processo de postagem e crescimento ocorre ao longo do dia sem a necessidade de qualquer intervenção humana.
Os Resultados
Os resultados são melhores do que você pode inicialmente imaginar. Eu basicamente tenho restaurantes jogando gift cards e refeições grátis no meu colo em troca de uma promoção no Instagram.
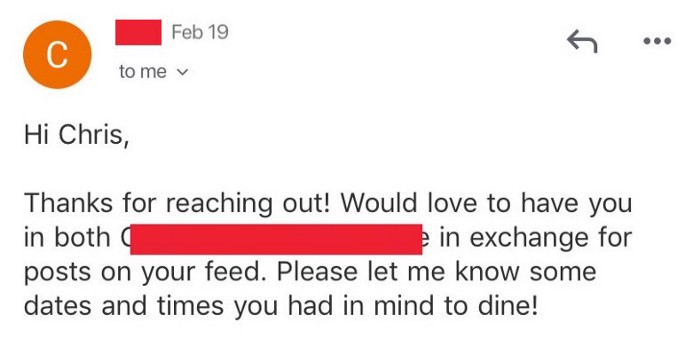
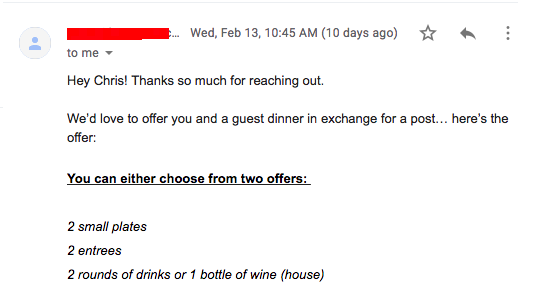
Através do poder da IA (Machine Learning), automação e ciência de dados — eu posso sentar e relaxar enquanto meu código faz o trabalho por mim. Ele age como uma fonte de entretenimento enquanto é meu vendedor ao mesmo tempo.
Espero que isso ajude a inspirar alguma criatividade quando se trata de mídia social. Qualquer pessoa pode usar esses métodos, sejam elas técnicas o suficiente para automatizar ou se precisam fazer isso manualmente. O Instagram é uma ferramenta poderosa e pode ser usado para uma variedade de benefícios comerciais.
Se você tem algum projeto legal de automação, me conta aí sua experiência via via Twitter ou e-mail!